반응형
목차
1. 문제 및 데이터
2. 코드작성
3. 코드풀이(1)- 데이터 전처리
4. 코드풀이(2)- 데이터 전처리 후
5. 참고 column_stack(), concatenate()
문제 : length가 25, weight가 150인 물고기가 도미인지 빙어인지 구분
데이터(도미와 송어의 길이와 무게)
#데이터
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
length = bream_length + smelt_length
weight = bream_weight + smelt_weight
코드작성
작성순서
1. 데이터를 리스트 형식으로 저장
2. train, test로 구분
3. KNeighborsClassifier로 훈련
4. 그래프 그리기(이웃 데이터 포함)
5. 데이터 전처리
6. 재훈련
7. 그래프 다시 그리기
import matplotlib.pyplot as plt
import numpy as np
#1. 데이터를 리스트 형식으로 저장
fish_data = [[l,w] for l,w in zip(length, weight)]
fish_data = np.column_stack((length, weight))
fish_target = np.concatenate((np.ones(35), np.zeros(14)))
#2. train, test로 나누기
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(fish_data, fish_target, stratify = fish_target, random_state = 42)
#3. 훈련 후 스코어
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
kn.fit(train_input, train_target)
kn.score(test_input, test_target)
#4. 그래프 그리기(이웃5개 포함)
plt.scatter(train_input[:,0], train_input[:,1])
plt.scatter(25, 150, marker = '^')
distance, indexes = kn.kneighbors([[25,150]])
plt.scatter(train_input[indexes,0], train_input[indexes,1], marker = 'D')
#5. 데이터 전처리
mean = np.mean(train_input, axis = 0)
std = np.std(train_input, axis = 0)
train_scaled = (train_input - mean) / std
new = ([25, 150] - mean ) / std
#6 재훈련
kn.fit(train_scaled, train_target)
#7. 그래프 다시 그리기
plt.scatter(train_scaled[:, 0], train_scaled[:, 1])
plt.scatter(new[0], new[1], marker = '^')
distance, indexes = kn.kneighbors([new]) #이웃 셈플 그리기
plt.scatter(train_scaled[indexes,0], train_scaled[indexes,1], marker = 'D')
plt.show()
코드 설명(1) - 전처리 전 학습
#사이킷런 패키지를 이용하려면 2차원 리스트를 만들어야 됨.
fish_data = [[l,w] for l,w in zip(length, weight)]
#zip()함수는 나열된 리스트 각각에서 원소를 꺼내 반환.
fish_data = np.column_stack((length, weight))
fish_target = np.concatenate((np.ones(35), np.zeros(14)))
#column_stack은 n*2 배열형태로 만들고,
#concatenate는 1*n 배열로 늘려서 만듬. 아래 사진 참고
#np.ones(), np.zeros()는 각각 원하는 개수의 1과 0을 채운 배열을 만듦.
#train, test 나누기(랜덤형식 42)
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(fish_data, fish_target, stratify = fish_target, random_state = 42)
#학습
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
kn.fit(train_input, train_target)
kn.score(test_input, test_target)
#데이터 그리기
import matplotlib.pyplot as plt
plt.scatter(train_input[:,0], train_input[:,1])
plt.scatter(25, 150, marker = '^')
#이웃 셈플 그리기
distance, indexes = kn.kneighbors([[25,150]])
plt.scatter(train_input[indexes,0], train_input[indexes,1], marker = 'D')
코드 설명(2) - 전처리 후 학습
#데이터 전처리(표준편차)
mean = np.mean(train_input, axis = 0)
std = np.std(train_input, axis = 0)
train_scaled = (train_input - mean) / std #브로드캐스팅(각각의 데이터에서 평균을 빼줌)
#전처리 하는 이유는 x와 y의 상대값을 맞추기 위해
#새로운 값(25,150)의 데이터 전처리
new = ([25, 150] - mean ) / std
#전처리 훈련
kn.fit(train_scaled, train_target)
#그래프 작성
plt.scatter(train_scaled[:, 0], train_scaled[:, 1])
plt.scatter(new[0], new[1], marker = '^')
distance, indexes = kn.kneighbors([new]) #이웃 셈플 그리기
plt.scatter(train_scaled[indexes,0], train_scaled[indexes,1], marker = 'D')
plt.show()
column_stack(), concatenate()
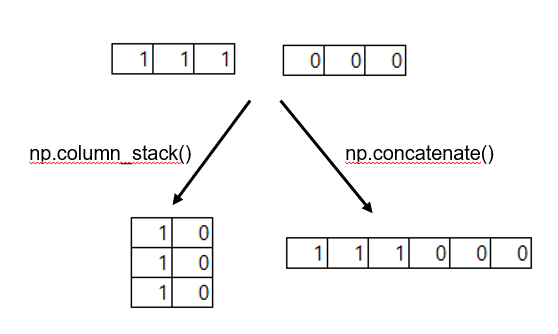
출처 : 혼자 공부하는 머신러닝 딥러닝
반응형
'코딩 > Python' 카테고리의 다른 글
| [코딩] 결정트리(f.혼자 공부하는 머신러닝 딥러닝) (0) | 2023.05.06 |
|---|---|
| [코딩] 이진분류,다중분류(f.혼자공부하는 머신러닝 딥러닝) (0) | 2023.05.05 |
| [파이썬] 혼자 공부하는 데이터 분석(06 데이터표현, 07 검증,예측) (0) | 2023.04.30 |
| [파이썬] 혼자 공부하는 데이터 분석(03-2 잘못된 데이터 수정하기) (0) | 2023.04.25 |
| 웹스크래핑(교보문고 ISBN으로 쪽수 가져오기) (0) | 2023.04.23 |

