반응형
- 순환신경망 : 이전에 처리했던 샘플을 재사용, 은닉층의 활성화 함수는 tanh(하이퍼블릭 탄젠트를 사용)
- 타임스텝의 은닉상태에 곱해지는 가중치가 하나 더 있음.
- 타임스텝 : 샘플을 처리하는 한 단계
- 셀 : 순환 신경망에서의 층
- 은닉상태 : 셀의 출력
- 모델 파라미터 수 : Wx + Wh + 절편
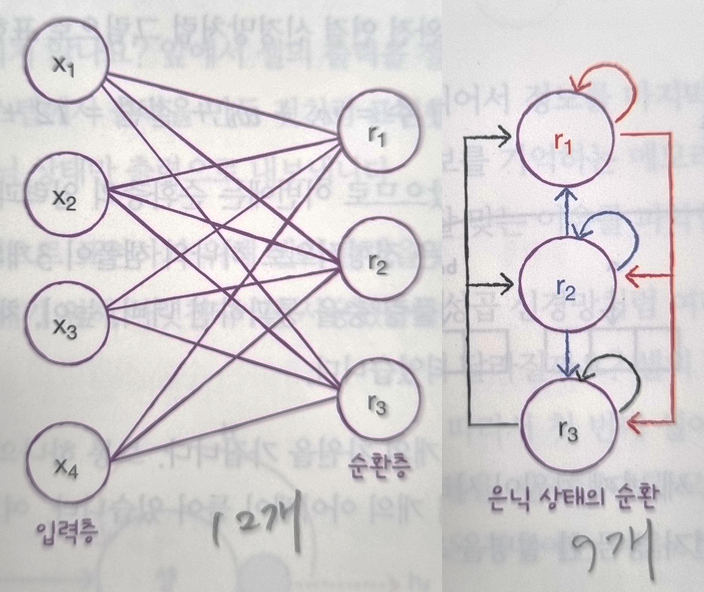
- 순환층은 일반적으로 샘플마다 2개의 차원을 가짐
- 하나의 샘플을 시퀀스라고 함
- 시퀀스 안에는 여러 개의 아이템이 있음('I', 'am', 'a', 'boy')
- 시퀀스의 길이가 타임스텝의 길이.
- 순환층을 통과하면 2차원 배열이 1차원 배열로 바뀜
- 이 1차원 배열의 크기는 순환층의 뉴런 개수에 의해 결정
- 순환층은 마지막 타임스텝의 은닉 상태만 출력으로 내보냄
데이터 준비
from tensorflow.keras.datasets import imdb
(train_input, train_target), (test_input, test_target) = imdb.load_data(num_words = 500)
print(train_input.shape, test_input.shape)
#>> (25000,) (25000,)
print(len(train_input))
#>> 25000
어떤 데이터인지 확인
print(len(train_input[0])) #>>218
print(len(train_input[1])) #>>189
print(train_target[:10]) #>>[1 0 0 1 0 0 1 0 1 0]
from sklearn.model_selection import train_test_split
train_input, val_input, train_target, val_target = train_test_split(
train_input, train_target, test_size = 0.2, random_state = 42)
import numpy as np
lengths = np.array([len(x) for x in train_input])
#>> array([149, 149, 581, ..., 204, 144, 141]
print(np.mean(lengths), np.median(lengths)) #>>238, 179
import matplotlib.pyplot as plt
plt.hist(lengths)
plt.xlabel('length')
plt.ylabel('frequency')
plt.show()
#>> 대부분 리뷰는 300자 미만
데이터 세팅
from tensorflow.keras.preprocessing.sequence import pad_sequences
train_seq = pad_sequences(train_input, maxlen = 100)
val_seq = pad_sequences(val_input, maxlen = 100)
#뒷글자 기준으로 100으로 길이를 맞춤, 100보다 적을 경우 앞 글자를 0으로 채움
print(train_seq.shape) #>> (20000,100)
print(train_seq[0].shape) #>> (100,)
RNN 만들기(Recurrent Neural Network, 순환신경망)
from tensorflow import keras
model = keras.Sequential() #층을 쌓기 위
model.add(keras.layers.SimpleRNN(8, input_shape= (100, 500)))
model.add(keras.layers.Dense(1, activation = 'sigmoid'))
#원-핫 인코딩
train_oh = keras.utils.to_categorical(train_seq)
val_oh = keras.utils.to_categorical(val_seq)
print(train_oh.shape)
#>> (20000, 100, 500) 각 원소마다 000001000...00 와 같이 배열 500개 만듦- simpleRNN클래스의 activatino 매개변수의 기본값은 'tanh'이므로 별도 지정 없음
- 입력값 100은 100개의 단어, 500은 자주사용하는 단어(초기에 설정함)
model.summary()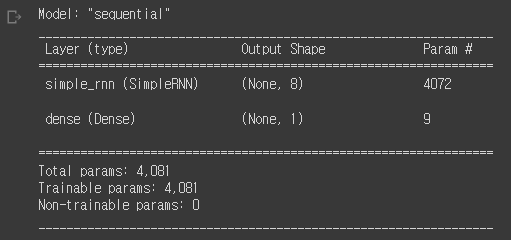
4072 = 500x8 + 8x8 + 8
=(500 원-핫 인코딩) x (은닉상태) + (은닉상태) x (뉴런개수) + 절편
순환신경망 훈련
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
#책에서는 RMSporp의 기본 학습률 0.001을 사용하지 않기 위해 별도 객체 지정
model.compile(optimizer = rmsprop, loss = 'binary_crossentropy', metrics = ['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-simplernn-model.h5', save_best_only = True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience = 3, restore_best_weights = True)
history = model.fit(train_oh, train_target, epochs = 100, batch_size = 64,
validation_data = (val_oh, val_target),
callbacks = [checkpoint_cb, early_stopping_cb])
#책에서는 epoch를 100으로 설정, 35에서 멈춤
그래프로 확인
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()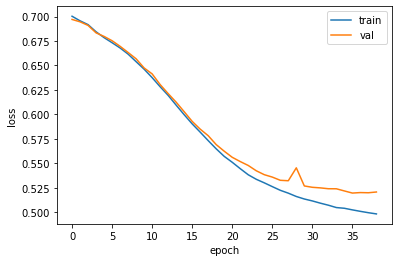
원-핫 인코딩의 한계 : 데이터가 너무 큼
print(train_seq.nbytes, train_oh.nbytes)
#>>8000000 4000000000 → 토근 한개를 500차원으로 늘려 500배 커짐
단어임베딩(각 단어의 고정된 크기의 실수 벡터로 바꾸어줌)
model2 = keras.Sequential()
model2.add(keras.layers.Embedding(500, 16, input_length = 100))
#500은 어휘 사전크기, 16은 임베딩 벡터의 크기, 100은 샘플 길이
model2.add(keras.layers.SimpleRNN(8))
model2.add(keras.layers.Dense(1, activation = 'sigmoid'))(예시) 'Cat'의 단어 임베팅 벡터
| 0.2 | 0.1 | 1.3 | 0.8 | 0.2 | 0.4 | 1.1 | 0.9 | 0.2 | 0.1 |
model2.summary()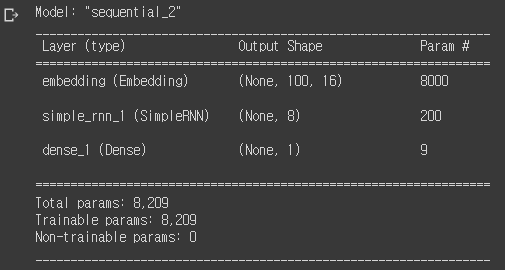
8000 = 500 x 16
200 = 16 x 8 + 8 x 8 + 8
단어임베딩 후 훈련
rmsprop = keras.optimizers.RMSprop(learning_rate = 1e-4)
model2.compile(optimizer = rmsprop, loss = 'binary_crossentropy',
metrics = ['accuracy'])
chechpoint_cb = keras.callbacks.ModelCheckpoint('best-embedding-model.h5',
save_best_only = True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience = 3,
restore_best_weights = True)
history = model2.fit(train_seq, train_target, epochs = 100, batch_size = 52,
validation_data = (val_seq, val_target),
callbacks = [checkpoint_cb, early_stopping_cb])
그래프로 확인
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()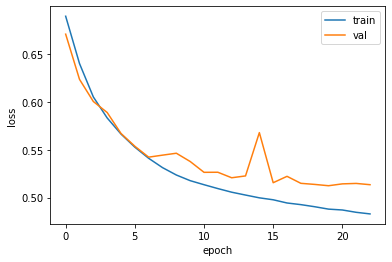
결론
원-핫 인코딩과 단어임베딩은 비슷한 성능을 내지만, 메모리 차원에서 단어임베딩이 훨씬 효율적
반응형