반응형
#데이터 및 준비
from tensorflow import keras
from sklearn.model_selection import train_test_split
(train_input, train_target), (test_input, test_target) = \
keras.datasets.fashion_mnist.load_data()
train_scaled = train_input / 255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)#모델 만드는 함수 정의
def model_fn(a_layer=None):
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation='relu'))
if a_layer:
model.add(a_layer)
model.add(keras.layers.Dense(10, activation='softmax'))
return model
#모델 컴파일
model = model_fn()
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=5, verbose=0)
print(history.history.keys()) #history에 어떤 값이 들어있는지 확인
#→ dict_keys(['loss', 'accuracy'])
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()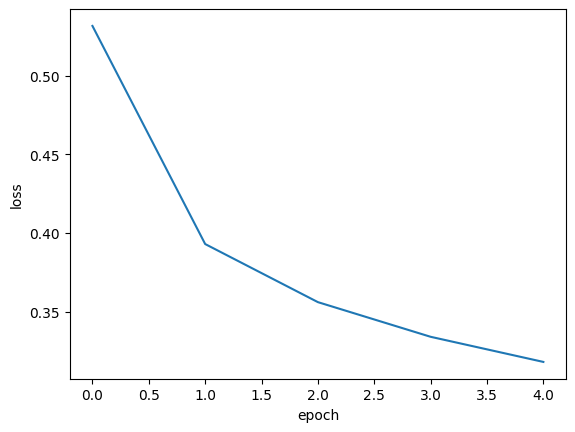
#에포크 횟수를 20으로 늘려서 모델 훈련 및 그래프 그리기
model = model_fn()
model.compile(loss = 'sparse_categorical_crossentropy', metrics = 'accuracy')
history = model.fit(train_scaled, train_target, epochs = 20, verbose = 0)
plt.plot(history.history['loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()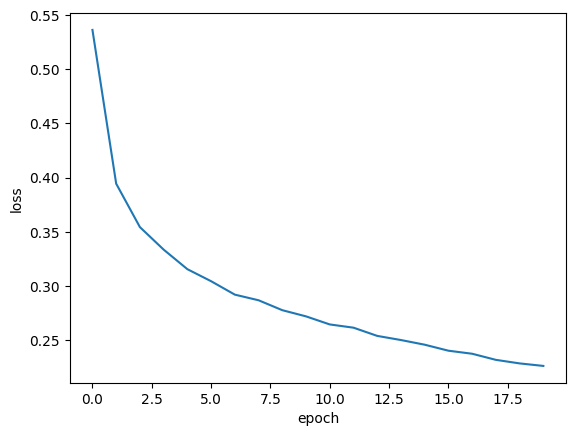
#에포크마다 검증손실 계산
model = model_fn()
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0,
validation_data=(val_scaled, val_target))
#history.history 딕셔너리에 어떤 값이 들어있는지 확인
print(history.history.keys())
#과대/과소적합 문제 조사하귀 위해 훈련손실, 검증손실 그래프 비교
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()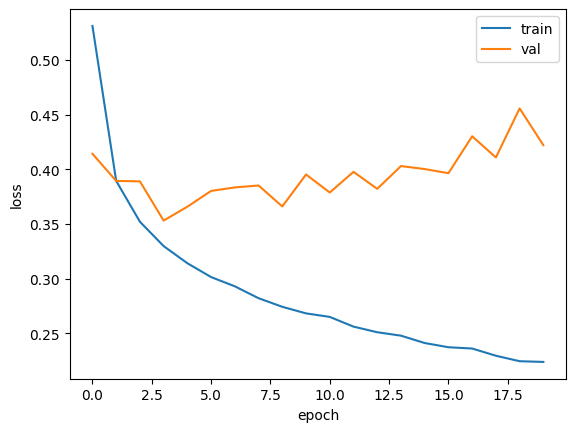
#콜백, 드랍아웃
model = model_fn(keras.layers.Dropout(0.3))
model.compile(optimizer = 'adam', loss = 'sparse_categorical_crossentropy', metrics = 'accuracy')
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-model.h5', save_best_only = True)
#modelcheckpoint는 에포크마다 모델을 저장, best_only=True는 가장 낮은 검증점수의 모델을 저장
early_stopping_cb = keras.callbacks.EarlyStopping(patience = 2, restore_best_weights = True)
#patience 2번연속 검증점수가 향상하지 않으면 훈련 중지
history = model.fit(train_scaled, train_target, epochs = 20, verbose = 0,
validation_data = (val_scaled, val_target),
callbacks = [checkpoint_cb, early_stopping_cb])
print(early_stopping_cb.stopped_epoch)
#>> 12 즉,13번째 에포크에서 훈련 중지, 최상의 모델은 11번째
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel(['train', 'val'])
plt.show()
#검증세트 확인
model.evaluate(val_scaled, val_target)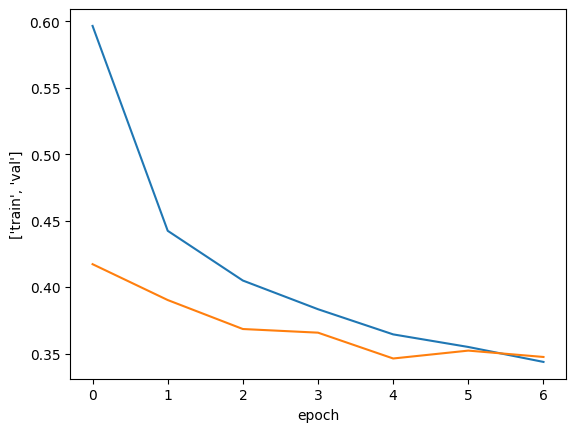
반응형
'코딩 > Python' 카테고리의 다른 글
| [코딩] 트리 앙상블(랜덤포레스트, 그라디언트부스팅, 엑스트라트리, XG부스트, 라이트GBM) - 혼자 공부하는 머신러닝 딥러닝 (0) | 2023.05.07 |
|---|---|
| [코딩] 결정트리(f.혼자 공부하는 머신러닝 딥러닝) (0) | 2023.05.06 |
| [코딩] 이진분류,다중분류(f.혼자공부하는 머신러닝 딥러닝) (0) | 2023.05.05 |
| [코딩] Neighbors 도미와 빙어 전처리 후 구분(혼자 공부하는 머신러닝 딥러닝) (0) | 2023.04.30 |
| [파이썬] 혼자 공부하는 데이터 분석(06 데이터표현, 07 검증,예측) (0) | 2023.04.30 |

