반응형
한글깨짐 현상때문에 분석보다 코드 수정이 더 시간이 훨씬 오래 걸렸다.
맷플롯플림과 씨본에서 한글을 사용하기 위해 폰트를 설치해야 한다.
1. 폰트 설치
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf2. 런타임 재시작

3. 코드 실행
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.rc('font', family='NanumGothic')
# 데이터 불러오기 및 처리
df = pd.read_csv('/content/sample_data/230630퀀트필터링.csv', error_bad_lines=False, encoding='euc-kr')
df_filled = df.fillna(0)
# 히트맵 그리기
plt.figure(figsize=(30, 15))
sns.heatmap(df_filled.corr(), annot=True)
# 그래프 출력
plt.show()
히트맵

히트맵 요약

히트맵 2
230630퀀트필터링(영익,매출)나머지 삭제.csv
0.07MB
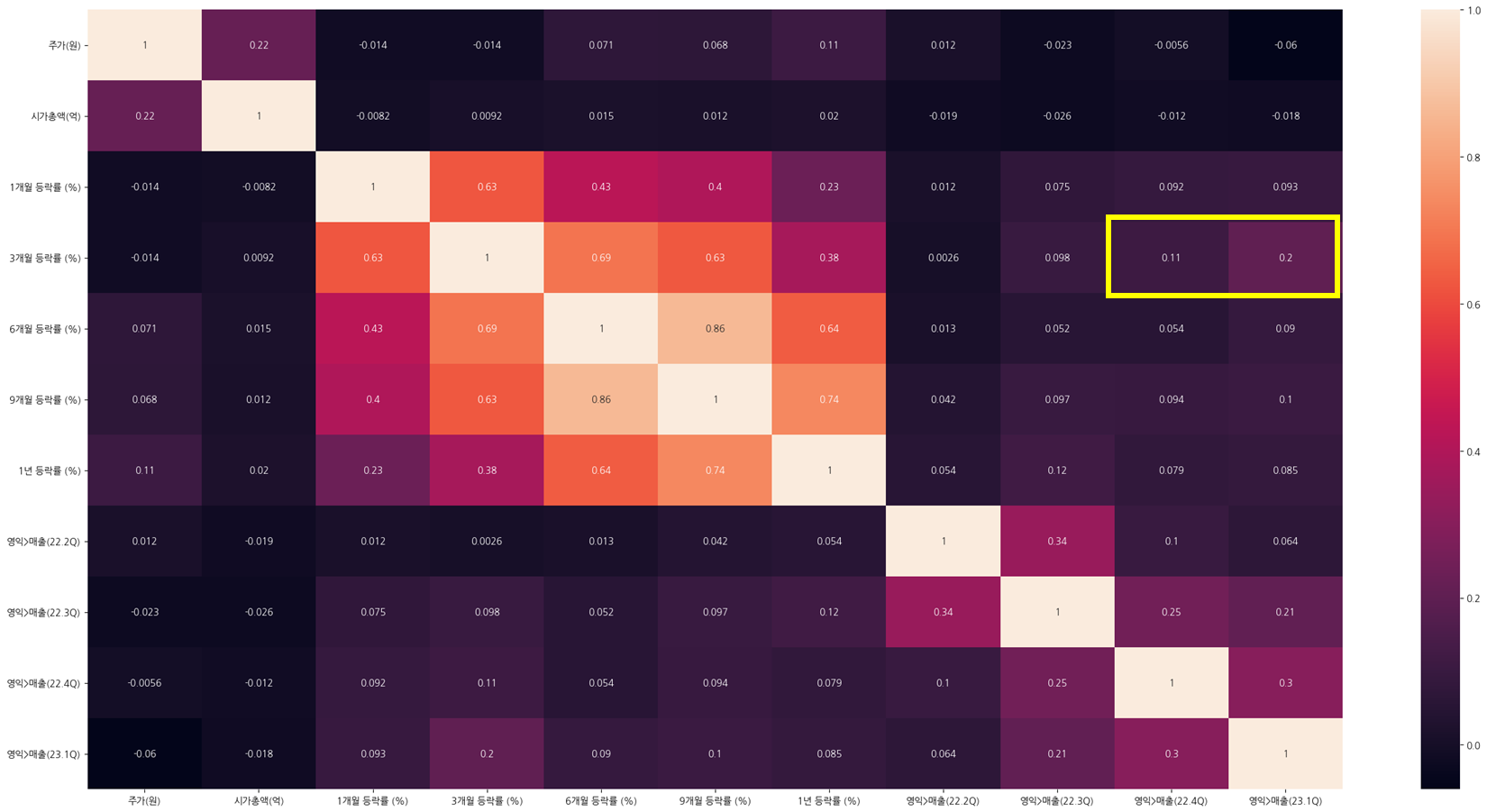
3개월 등락률이 영업이익>매출액 구간에 미묘하게 변화를 주지만 내가 찾던 만족은 아니었다.
참고
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.rc('font', family='NanumGothic')
# 데이터 불러오기 및 처리
df = pd.read_csv('/content/sample_data/230630퀀트필터링(영익,매출)나머지 삭제.csv', error_bad_lines=False, encoding='euc-kr')
df_filled = df.fillna(0)
# 히트맵 그리기
plt.figure(figsize=(30, 15))
sns.heatmap(df_filled.corr(), annot=True)
# 그래프 출력
plt.show()
영업이익과 매출액, 3개월 등락률의 상관관계
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
df = pd.read_csv('/content/sample_data/230630퀀트필터링(영익,매출)나머지 삭제.csv', error_bad_lines=False, encoding='euc-kr')
df_filled = df.fillna(0)
X = df_filled.iloc[:, [10,11]].values
y = df_filled.iloc[:, 5].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
#정규화
ss = StandardScaler()
ss.fit(X_train)
train_scaled = ss.transform(X_train)
test_scaled = ss.transform(X_test)
# 랜덤 포레스트 모델 생성 및 학습
rf = RandomForestRegressor(n_estimators=3, random_state=42)
rf.fit(X_train, y_train)
# 변수 중요도 확인
importance = rf.feature_importances_
print("중요도 :", importance)>>중요도 : [0.134 0.865]
반응형
'주식' 카테고리의 다른 글
| 넥스틴 기업분석(패턴 결함 검사) 및 경쟁기업 (0) | 2023.08.29 |
|---|---|
| 식각 파츠(Ring, Electrode, Si/SiC), 시장, 업체별 정리(티씨케이, 하나머티리얼즈, 월덱스, 케이엔제이) (0) | 2023.08.25 |
| 증착(LPCVD, PECVD, ALD)과 시장 업황, 관련 기업(유진테크, 주성엔지니어링, 원익IPS, 테스) (0) | 2023.08.24 |
| 식각의 모든 것(원리, 장비, 산업, 시장, 기업) (0) | 2023.08.20 |
| 주식분석(1), 퀀트와 머신러닝(랜덤포레스트)을 이용 (0) | 2023.07.04 |


